字符集与编码之BOM
大端法:以两个UTF-16的编码0x0048与0x4F60为例,写成00 48 4F 60,00与4F都属于高位,这种高位在前的称之为大端法(Big endian)。
小端法:如果书写成48 00 60 4F,这种低位在前的写法称之为小端法(Little endian)
其实大小端法是从存储层面考虑的。
如上,高位的字节00放到了低地址0x0000上,低位的字节48却放到了高地址0x0001上;与大端法相反,小端法的高低字节反而与地址的高低位自然地对应上了。
需要强调的是,所谓大小端仅仅是字节间的关系,只有多字节情况才会有所谓的端法,而通常又在偶数字节情况下更为普遍,如UTF-16,UTF-32,这样才能更好分出“两个端”来。
BOM是byte-order mark的缩写,为Unicode标准为了用来区分一个文件是UTF-8还是UTF-16或UTF-32编码方式的记号,又称字节序。它是插入到以UTF-8、UTF16或UTF-32编码文件开头的特殊标记,用来标记多字节编码文件的编码类型和字节顺序(big-endian或little- endian)。
UTF-8以单字节为编码单元,并没有字节序的问题,在UTF-8编码中,其自身已经带了控制信息,如1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx,其中1110就起到了控制作用,所以不需要额外的BOM机制。
而UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?这是UTF-16文件开头的BOM就有作用了。
在UTF-8文件中放置BOM主要是微软的习惯,BOM其实是为UTF-16和UTF-32准备的,微软在UTF-8使用BOM是因为这样可以把UTF-8和ASCII等编码明确区分开,但这样的文件在Window以外的其他操作系统里会带来问题。
以Windows下的文本文件为例:
Windows下保存txt可以选择ANSI、Unicode、Unicode big endian 、UTF-8四种编码方式。
- 其中ANSI是默认编码方式,对于英文文件采用ASCII编码,简体中文采用GB 2312(只针对Windows简体中文版,如果是繁体中文则采用Big5编码)
- Unicode其实是UTF-16 endian big编码方式,是带有BOM的小端序UTF-16
- 而Unicode big endian则是带有BOM的大端序编码方式
Windows平台为何使用小端法呢?说起来与CPU制造商英特尔(Intel)又有很大关系。这两者我们又常叫它们为Wintel联盟。(Wintel=Windows+Intel)
内存(Memory)中使用端法其实又是受到寄存器(Register)中使用的端法的影响,因为两者之间经常要来回拷贝数据。英特尔的CPU就使用了小端法。
Windows下用记事本分别以UTF-8、Unicode big endian、Unicode编码方式保存“Python”,以16进制查看文件内容。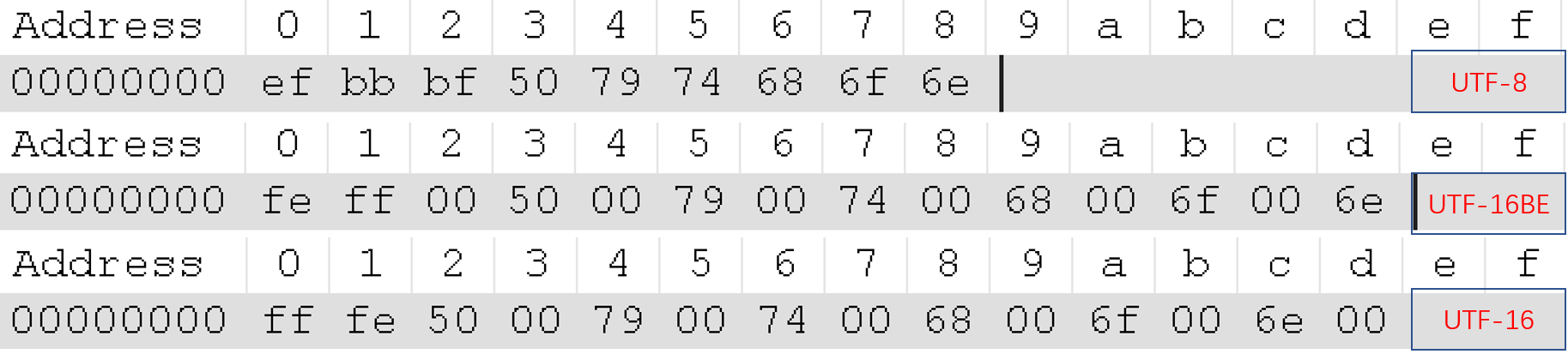
从上图中可以看出:
- UTF-8的BOM是EF BB BF
- UTF-16LE的BOM是FF FE
- UTF-16BE的BOM是 FE FF
JVM中缺省是大端法,这与Windows平台下缺省为小端法恰好相反。
参考:
https://blog.csdn.net/wzd2012/article/details/70237029
https://blog.csdn.net/wzd2012/article/details/70237029
https://www.cnblogs.com/signheart/p/c3b1000186199e89d4e02c33f39ed418.html
https://www.cnblogs.com/yizhenfeng168/p/6938149.html
https://www.cnblogs.com/leesf456/p/5317574.html
http://djt.qq.com/article/view/658?ADTAG=email.InnerAD.weekly.20130902&bsh_bid=281085951